
There are numerous reasons organisations are interested in data sharing. However, deduplication is one of the most common reasons. This is the third part of a short series of posts looking at different options for data sharing especially for deduplication purposes.
Centralised data layers were key to both Model 1 and Model 2. Model 3 is a slight variation of 1 & 2 using some clever technology so that little data is exposed to another agency.
In this model, the agencies wanting to deduplicate datasets agree on a standard way to create a hash as a unique identifier for each person. There are many ways to create a hash, the key is that every agency does it the same way. Once the unique identifier is created, it and only it, is put into the data layer. The data layer can be ‘owned’ by a single agency (Model 1) or held within a data trust (Model 2).
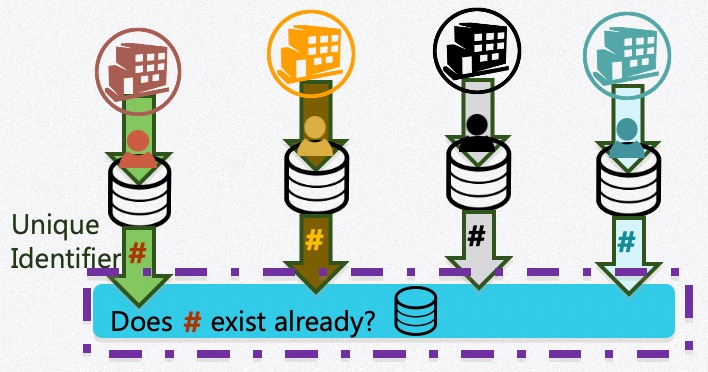
However, before putting unique identifier into the data layer, it ‘asks‘ the data layer if that unique identifier already exists. The data layer ‘responds’ with a yes or a no. If the unique identifier does not already exist, it is added, if it does already exist, then it is not added.
This is using the concept of a zero knowledge proof. The idea is that if deduplication is truly the purpose, I don’t need to know any details about you, I just need to know if you are unique.
While this technology is widely available now, it would be huge change for the humanitarian community. It potentially would require us to ‘allow’ other agencies to ‘ping’ our servers. There is very little liability change for each agency.
This model would address aspects of the power dynamics between agencies as minimal information can be deciphered from the unique identifier even if you could reverse engineer it. Therefore the data layer provider becomes a service for the community with little ‘power’ attached to it.
In my view, one of the unfortunate things of this model is that the person about whom the data is, still has no access to it. The data is effectively ‘owned’ and controlled by the agency collecting the data.
0 Comments